
The model behind Git


When it comes to version control systems (VCS), we can start naming a few of the most popular, like Subversion, Mercurial, Perforce, etc. Nevertheless, at this time our focus will be on Git, which is the one we commonly use at 10Pines. This tool allows us to work in a fast and simple way inside our agile development model.
Git was created by Linus Torvalds in the year 2005, after Bitkeeper (another VCS) stopped being free. Taking Bitkeeper as starting point, Linus and his team created a VCS according to the following metrics:
-
Speed
-
Simple design
-
Strong support for non-linear development (thousands of parallel branches)
-
Fully distributed system
-
Capability of handling large projects
Based on such principles, they implemented an object repository using a directed acyclic graph (DAG), like the one below:
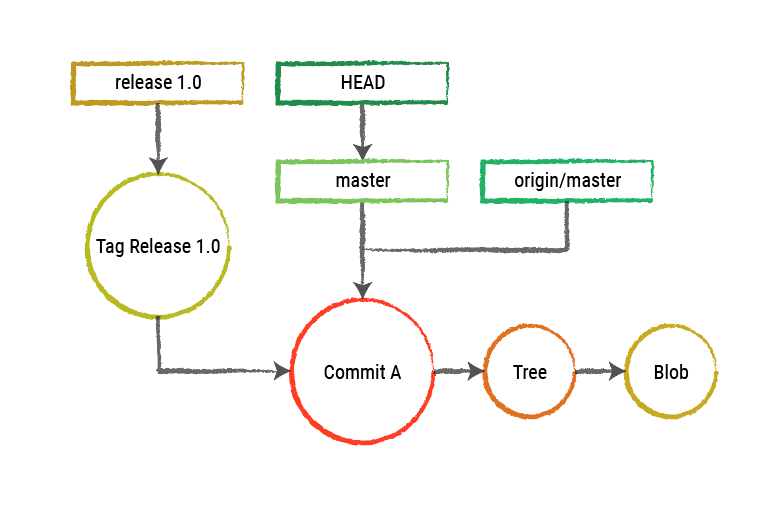
Each circle represents an object stored inside the repository, and the rectangles represent the references that serve as entry points for the objects.
Objects
Each object is a node inside the DAG, and at the same time, the root for a subgraph consisting only of Trees and Blobs, which represents a particular state for the entire project.
There are 4 types of objects inside Git:
Blob - Blobs represent files inside the project.
Tree - Trees represent folders inside the project. The top one is related to the root directory.
Commit - Commits are a change inside the project, represented through a reference to a Tree. That Tree plus all the subgraph starting there is one of the repository's current states. Each Commit has a reference to it's parent, creating a chained link. The changes applied by a Commit are the differences between itself and it's parent node.
Tag - Tags are objects that point to a specific moment of the repository, storing a reference to a specific Commit. They are generated by the tag operation, and along with the Commit reference, they store a title, a comment, and optionally a GNU Privacy Guard (GPG) which increases security.
Every object inside Git has an ID generated by applying a hash function (SHA1) to the object. For example, for Commit we need the following data:
- The source tree of the commit
- The parent commit
- The author info
- The committer info (can be different)
- The commit message
- A NULL-terminated header that gets appended containing the word "commit", and the length in bytes of all of the above information:
tree c0fa4aaf5417a6f6d829eead05ac4e021d77bb25
parent 859447f78aab10084c212a2c372b6ce809b3f2a2
author Martin Gonzalez <martingonzalez@gmail.com> 1526324470 -0300
committer Martin Gonzalez <martingonzalez@gmail.com> 1526592286 -0300
Changes after rebase
Data required for Commit ID, example taken from: https://gist.github.com/masak/2415865
References
There are 4 types of references inside Git:
Release reference (Yellow): Release references are generated alongside, and must always point to, a Tag. They are immutable, meaning they can't suffer any change.
Branch reference (Green): Branch references always point to a Commit object, which changes every time a new Commit is added to the Branch.
Remote branch reference (Grey): Remote branch references are similar to Branch references, but follow a branch of a remote repository. In the above picture, the remote branch reference is pointing to a branch named master, which is a remote branch in a repository named origin[1].
HEAD reference (White): HEAD references point to the Commit that will be the parent of the next Commit to be created. When a commit operation is done, the reference switches to the new one.
Conclusion
These days the usage of a version control system (VCS) has become an essential tool for people who works with software. Doing a good job with VCSs is key, because it increases the project’s speed and allows us to recover faster from mistakes, one of our biggest problems.
A tool like Git requires a lot of trial and error. The more you know about it, the less are the chances of making a mistake. My recommendation is: be patient, ask for help if you need to but don't be afraid to use such a powerful tool.
Thanks to Pablo Belaustegui for sharing with me his knowledge and personal experience about Git.
Remote repositories can be on your local machine. It is entirely possible that you can be working with a “remote” repository that is, in fact, on the same host you are. The word “remote” does not necessarily imply that the repository is somewhere else on the network or Internet, only that it is elsewhere. Reference ↩︎