
Generando queries SQL con un poco de aiuda
¿Cansado de escribir SQL a mano? ¿Se complica pedir ayuda a la IA de turno por falta de contexto? Este post te podría interesar!

En 10Pines, buscábamos poder explorar los datos de nuestro backoffice sin la necesidad de que los usuarios tengan que saber SQL o desarrollar interfaces específicas para cada reporte. Para abordar este desafío, decidimos implementar una solución que genera queries SQL a partir de lenguaje natural, adaptada a nuestro contexto de negocio, todo corriendo localmente.
¿Por qué localmente? Porque es un requerimiento bastante común solicitado por los clientes, para asegurarse que sus datos se mantengan dentro de sus servidores ya sea por razones de seguridad o por cumplir con regulaciones específicas. De esta manera, garantizamos que la generación de consultas no comprometa la privacidad ni seguridad de los datos.
La idea es poder hacer preguntas del estilo: “¿Cuántos pinos ingresan por año?” y que el sistema pueda respondernos con una query SQL.
SELECT EXTRACT(YEAR FROM fecha_registro) AS anio, COUNT(entidad_id)
FROM entidades
WHERE "categoria" = 'Pino'
GROUP BY anioPara lograr que el sistema comprenda preguntas en lenguaje natural, lo que hicimos fue utilizar un LLM. Pero… ¿Qué es un LLM?
¿Qué es un LLM?
Un LLM (Large Language Model) es un modelo de lenguaje que se entrena para comprender y generar texto en lenguaje natural. Estos modelos son redes neuronales masivas que aprenden a identificar patrones en grandes cantidades de texto, permitiéndoles responder a preguntas o realizar tareas específicas en lenguaje natural.
Entonces, si el LLM ya está pre-entrenado e incluso existen modelos específicamente entrenados para generar código, ¿por qué no usamos un LLM y ya? A priori, el problema parece estar resuelto. No obstante, estos modelos pueden carecer de cierto contexto específico del problema. Por ejemplo, volviendo a la pregunta del ejemplo inicial: "¿Cuántos pinos ingresan por año?", es importante destacar específicamente la palabra “pino” ya que probablemente cuando a un LLM se le habla de pinos, probablemente esté entrenado para entenderlo como “árbol perenne (que crece y mantiene hojas durante todo el año) que pertenece a la familia de las coníferas” cuando, en realidad, nosotros nos queremos referir a cualquier persona perteneciente a 10Pines.
¿Cómo podemos resolver esta falta de contexto? Existen 2 formas, podemos hacer un fine tuning al LLM o utilizar una técnica llamada RAG “Retrieval Augmented Generation”.
Exploremos ambas….
Fine-tuning vs. RAG
Fine tuning consiste en tomar un modelo base y re entrenarlo con nuevo contenido específico de nuestro negocio. El mismo requiere una gran cantidad de información y tener conocimiento de técnicas de entrenamiento de LLMs, además de un buen hardware para poder correrlo. Es importante considerar que el fine tuning es una buena práctica si los datos no van a cambiar con el tiempo ( son mayormente estáticos), ya que el costo de re entrenamiento es alto.
Por otro lado, RAG no tiene un costo computacional alto, funciona muy bien para contextos con datos dinámicos y, además, una vez entrenado sirve para diferentes LLMs. Como desventaja, la eficiencia del RAG depende mucho de la calidad del contexto brindado, esta puede empeorar ante la falta de información importante o bien porque el mismo no fue bien estructurado.
Ahora que exploramos las características de ambas técnicas, la pregunta es: ¿cuál elegimos y por qué? Nosotros nos volcamos por un RAG ya que los datos de dominio iban a cambiar con bastante frecuencia y queríamos poder adaptarnos. Pero como buscábamos hacer un experimento, no queríamos hacer la implementación del RAG desde cero, es por esto que investigamos un poco y encontramos exactamente lo que estábamos buscando: Vanna AI, un paquete de Python que brinda un RAG preparado para generar SQL a partir de lenguaje natural.
Vanna cuenta con algunas otras particularidades que nos servían, como el hecho de que es open source, puede correr localmente, soporta múltiples bases de datos y se conecta con cualquier LLM. Nosotros, como LLM utilizamos LLaMa 3.1 (en su versión 8B) mediante ollama para poder correrlo localmente.
¿Cómo funciona Vanna?
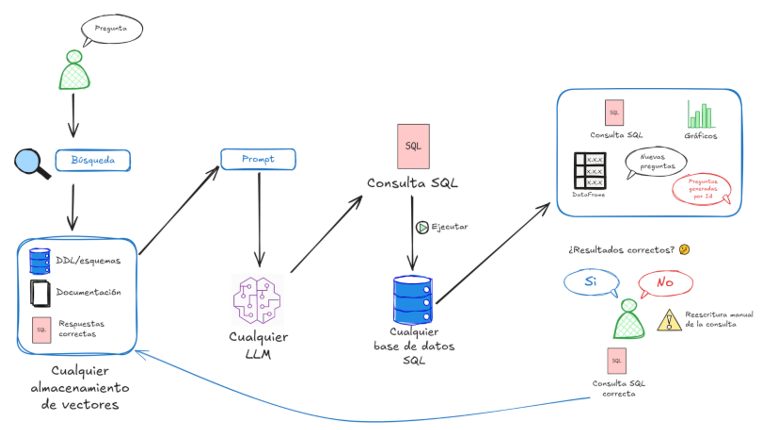
- Partiendo de la pregunta del usuario, realiza una búsqueda de contenido relacionado
- ¿Cómo? Se convierte el texto en “embeddings” que no son nada más que vectores
- Una vez convertido en vectores, se puede calcular la distancia con otros vectores
- Es así que se buscan los más cercanos y se devuelven
- Una vez obtenida la documentación relacionada, se genera el prompt, que además de la pregunta del usuario, tiene el contexto obtenido en el paso anterior
- El prompt se le pasa al LLM que genera un resultado SQL
- Este resultado se puede ejecutar e incluso generar gráficos en base a este
- También se puede preguntar al usuario final si los resultados fueron correctos.
- De ser correctos se pueden guardar en la base de conocimiento
- De no ser correctos se puede corregir el query y guardar el query corregido en la base de conocimientos
Entrenarlo fue bastante fácil utilizando la API que provee. Existen 4 formas de entrenamiento:
- DDL (Lenguaje de Definición de Datos)
- Documentación
- SQL
- Pares de Pregunta/Respuesta (SQL)
Algunos ejemplos
DDL
vn.train(
ddl="""
CREATE TABLE public.dispositivos (
id bigint NOT NULL,
descripcion character varying NOT NULL,
habilitado boolean DEFAULT true NOT NULL,
categoria_id bigint NOT NULL
);""")Documentación
vn.train(
documentation="Para nosotros un Pino es un registro de la tabla entidades con 'type' igual a 'Pino'"
)SQL
vn.train(
sql="SELECT * FROM entidades WHERE nombre LIKE '%Diego%'";
)Pares de Pregunta/Respuesta (SQL)
vn.train(
question="Cuales son los nombres de todos los pinos activos?",
sql="select id, nombre from entidades e where e."type" = 'Pino' AND fecha_salida IS NULL"
)Prompt
Como mencionamos anteriormente, luego de obtener los documentos más relevantes para nuestra pregunta, Vanna generará un prompt para pasarle al LLM, brindándole la mayor cantidad y calidad de contexto posible. Este prompt tiene el siguiente formato:
Eres un experto en PostgreSQL. Por favor, ayuda a generar una consulta SQL para responder la pregunta. Tu respuesta debe basarse ÚNICAMENTE en el contexto proporcionado y seguir las pautas y las instrucciones de formato de la respuesta.
… <info de tablas relevantes> …
Contexto Adicional … <info de documentación relacionada> …
Usa la(s) tabla(s) más relevante(s).
Si la pregunta ya ha sido hecha y respondida antes, por favor repite la respuesta exactamente como se dio antes. Asegúrate de que la salida SQL sea compatible con PostgreSQL, ejecutable y libre de errores de sintaxis. <info de preguntas/sql anteriores relacionadas>.
<Pregunta del usuario>
Conclusiones
Las posibilidades que nos brinda Vanna son muchas, ya que es fácilmente integrable con Slack u otras herramientas. Pero, más genéricamente hablando, se pueden realizar cosas útiles como explorar datos utilizando lenguaje natural sin la necesidad de tener que utilizar software de BI.
Ahora bien, puntualmente sobre nuestro experimento podemos decir que:
- Vanna cumplió con las expectativas para hacer un prototipo rápidamente.
- Nos permitió entrenar un RAG rápidamente y de una forma fácil.
- Fue fácil mantenerse al día con los cambios y hacer correcciones de nuestra base de conocimientos.
- Pude correr LLaMa 3.1 8B en una laptop con un i7 y gráficos integrados sin mayores problemas
- A mayor y mejor contexto, mejores fueron los resultados
- Simplemente con el DDL del schema no fue suficiente como entrenamiento
Los invito a que hagan sus pruebas y nos compartan sus experiencias.