
Clean Code Cleanups
I’ll walk you through different stages of code cleanup, and things to have in mind to make it in an efficient way, based on my experience.


Intro
Once in a while, we face the task of cleaning up a piece of software. There could be several reasons for deleting code: users don't actually use it (or it is causing a bad experience), we made an experiment and we already got results, there was a temporary business need that is no longer relevant, or maybe it's better to remove it because we can't afford the maintenance cost; in other words, it is adding more problems than business value.
Having features partially cleaned up is one of the most common problems we can see on any piece of software. It increases the level of uncertainty in the project, and a feeling of "so many things to fix that I don't know where to start". I'll walk you through different stages of cleanup, and things to have in mind to make it in an efficient way, based on my experience.
Prep for cleanup
Most of the time you know that a piece of code is going to disappear. You can smell it (I heard about a skill of senior developers that is hard to explain which is an ability of smelling things like complexity). If that's the case, you can start marking the code to easily find it later on, when you finally decide to make the actual cleanup.
I remember in one of the teams I worked on, we had to implement the V2 of a feature (which was a rewrite of a successful experimental feature). When we made the project kickoff, in addition to the V2 work, we added two additional tasks to our backlog:
- Mark the V1 code for deprecation (this could be done right away, independently of the progress on the V2 implementation)
- Remove V1 code and data models associated (this might need more than 1 PR)
I still remember my first attempts to remove code: they were not so well organised, and they always took more time to complete than I initially expected. I clearly underestimated the task. Lesson learned!, Nowadays, I always try to leave marks in the code when appropriate.
Another cool thing on one of our client projects is a simple deprecation mechanism, where you can mark your code using comments with a specific format:
# DEPRECATE 2020-12-01; ticket number; brief description
The cool thing about this snippet is that it has an expiration date. A script on the pre-commit goes through all the deprecation marks and looks for expired ones. If it finds any, a warning is raised and you have to make a decision: bumping the date, or addressing the deprecation. It's a simple attempt to avoid leaving legacy code forever (thus becoming more legacy as time passes by).
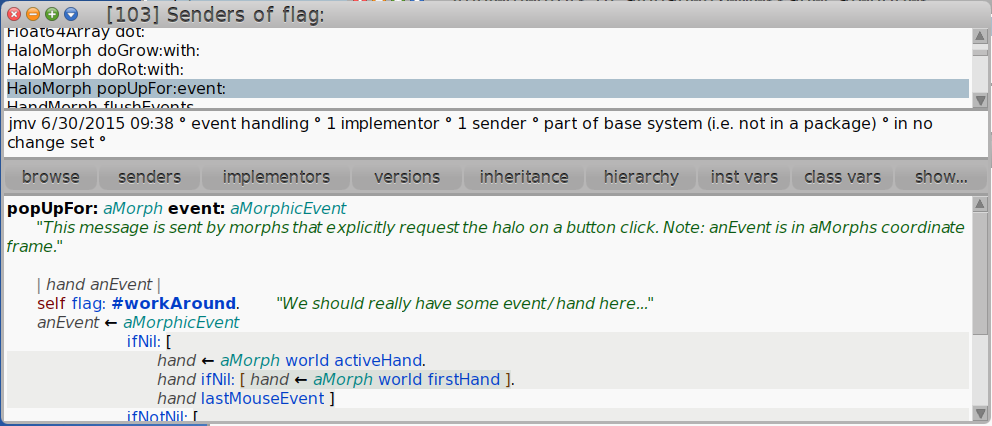
Another flagging mechanism I use a lot is in Cuis Smalltalk. There's a very simple built in feature: you can call the #flag: method on any object (because the method is defined in Object) and then you can easily find it across your program. It's a live deprecation notification, because it is code. You can play with metaprogramming and make cool things out of it: like measuring the technical debt. #flag: receives an argument that you can use as a way to categorize your mark.
Here’s how it looks when we find all the places where #flag: is used plus a concrete example:
Top-down or bottom-up?
Code cleanup goes smoothly if we have a strategy. If you start deleting code randomly, it's very likely to leave things out. So I don't recommend that “strategy” (Or, actually, lack of it, :-)).
In the same way you can build a piece of software, you can clean it up: it could be top-down or bottom-up.
Top-down means starting from the UI, looking at all the code it's being referenced there and start deleting: if it is a web application, the starting point is the HTML, then JS logic, CSS rules, assets, translation keys, and so on. Then proceeding with communication with the backend (routes / controllers), then services or other objects involved, and lastly the models / data models.
Bottom-up is exactly the opposite: for instance, removing models and see where it breaks: that is the next thing to address, until you get to the outermost part, that could be the UI.
I feel more comfortable with the top-down approach, because you first remove usages and then definitions (if they are not used somewhere else). Code breaks progressively, while in the opposite approach it is broken in the first touch and it remains broken until you finish.
To find unused code, in addition to finders in your IDE, you can rely on linters or tools like unused, which is technology agnostic, and it's easy to run on any project. I used it on Ruby on Rails and it caught a lot of code I missed on my initial searches. I strongly recommend it.
Things to have in mind
Linting rules: sometimes, we can build our custom logic to detect unused code. One that I’ve seen in one of the projects I worked on is a script to detect unused i18n keys (one of the most common pieces of code that gets forgotten in a cleanup).
Tests coverage: before start removing anything, it is a good idea to measure how covered by tests is the code affected by the cleanup, or how confident we are with the existing tests (harder to measure because it’s subjective). Tests should give us feedback of the cleanup process: if we have few tests, we could be under a false feeling of success. And if you don't have any test, it is a good time to write more or you will spend a bunch of time on manual testing.
Manual regression testing: not everything can be caught by automated tests, so we need to know how to test manually, focusing on the most critical areas and parts that could be affected by the change.
Metaprogramming: cleaning code that makes use of metaprogramming is challenging. And on dynamic languages, it is even harder. We can’t just do a text-based search to decide if we should remove a piece of code or not. What I do on these cases is to find where metaprogramming is used (in Ruby, that could be when someone is using send or method_missing, or eval -HOPEFULLY NOT!-) and check if that code could affect or be affected by the cleanup I’m doing.
Conventions (could be seen as a particular case of metaprogramming): sometimes, we can’t find exact matches of terms in the code, but there is a functionality that a framework like Rails could be providing. Rails can make, among other conventions, plural/singular conversions automatically for you, so when searching code, you need to have that in mind. For instance, in things like routing, store#index means to call an index method on a StoresController.
Not just business logic: sometimes removing pieces of code imply removing libraries, configuration files, test fixtures, translation strings, assets, CI setup tasks, and more auxiliary things.
Commenting code instead of removing is not an option: DO NOT LEAVE COMMENTED CODE. Commented code is dead and confusing.
Version control history is your best friend: If you look at the original commit/PR that added the code you want to remove, you might find related groups of code that can be probably deleted together. Also if you have the chance to talk with the person or team that added this feature, probably you could gather additional relevant information.
Be prepared for the worst: I usually make a revert PR in case something breaks, and let my team (or the person on-call if there are any) know when it is going to be merged/deployed. And if it is possible to make it in small PRs, go for that!
For the future: if you are adding new code to your system, think about how you can clean it up. Is there anything that I can help today as the creator of this feature, in case someone (that could be also me) wants to clean it up in the future? Can some comments be helpful to explain WHY a piece of code was introduced? If I have to use metaprogramming (pro-tip: this should be your last resource), how can I make it “not obscure”?
Conclusions
I'd just say do not underestimate code deletion tasks. There are a lot of things to have in mind. Make it part of your project backlogs, and think about strategies (like the top-down I recommend) to move towards cleaner and stronger codebases.