
Primeros pasos en orquestación de containers con Docker Swarm
Docker es una herramienta indispensable hoy en día. A medida que la arquitectura crece el proceso se vuelve complicado si no poseemos herramientas específicas. La solución: Swarm.


Traducido por Nicole Blasco
If want to see this post in English, click here.
Introducción
Docker se ha convertido en una herramienta indispensable en mi día a día como desarrollador. Desde un principio he intentado incorporarlo en los proyectos en los que participo y, con el tiempo, logré usarlo progresivamente para:
- Levantar mis "componentes auxiliares" de desarrollo (motores de bases de datos, proxies inversos, servidores redis, etc.)
- Crear definiciones estáticas de mis componentes auxiliares con
docker-composepara compartir entre entornos de desarrollo. - Scriptear la creación de mis propios componentes en
Dockerfilese incluirlos en eldocker-compose.ymlpara facilitar el desarrollo de arquitecturas distribuidas. - Usar un
docker registryprivado para publicar mis imágenes y utilizarlas en eldocker-compose.yml. - Crear un
docker-compose.ymlalternativo para realizar el despliegue a distintos ambientes. - Simplificar los despliegues apoyandome en
docker-machinepara provisionar o manejar servidores.
Si bien docker-compose y docker-machine ayudan en la administración de servidores, a medida que la infraestructura crece horizontal y verticalmente, el proceso se empieza a volver complicado si no poseemos herramientas específicas para este fin.
La solución que propone Docker para esta problemática se llama Swarm.
Qué es Docker Swarm?
Swarm es una funcionalidad de Docker usada para la organización de clústers de services, que sirve para facilitar la distribución y administración de sistemas dockerizados en infraestructuras multi-host. Para utilizarla no hace falta más que tener instalado el engine de docker ya que desde la versión 1.12 está incluído nativamente en el mismo. Algunos de sus beneficios son:
- CLI API para creación y administración de clústers de servidores.
- Modelo de Service simple y declarativo.
- Escalamiento de Services según la carga.
- Actualizaciones continuas.
- Facil y seguras redes distribuídas.
- Balanceamiento de carga.
- Descubrimiento de Services.
A continuación voy a hacer un repaso sobre la configuración de un Swarm y el despliegue de una aplicación de micro-servicios en una infraestructura de 3 servidores.
Pre-requisitos
Para seguir este paso a paso hay que partir de un host con las herramientas principales de docker ya instaladas (docker / docker-compose / docker-machine). Para el ejemplo, voy a usar un host Ubuntu (aunque se puede realizar lo mismo en Windows, Mac u otros distros de Linux, con pequeñas adaptaciones). También es necesario tener instalado Virtualbox para la creación de maquinas virtuales.
A su vez, voy a intentar enfocarme en los comandos referentes a Swarm, por lo que es recomendado tener una noción básica de las herramientas mencionadas.
Preparación de las máquinas
El primer paso para lograr un Swarm consiste en la creación y provisión de las máquinas que servirán de nodos para el cluster. En nuestro caso vamos a usar docker-machine para provisionar 3 máquinas virtuales en nuestro host. Vale aclarar que ésto no es necesario para la creación de un Swarm. Basta con tener hosts que puedan comunicarse entre si a través de los puertos que docker requiere (por ejemplo, diferentes máquinas EC2 en AWS).
$ docker-machine create --driver virtualbox manager
$ docker-machine create --driver virtualbox nodo1
$ docker-machine create --driver virtualbox nodo2
Nótese que hemos creado una máquina con el nombre manager. Ésto constituye una de las definiciones principales de Docker Swarm:
Al menos uno de los nodos de un Swarm deberá tener el rol de Manager, mientras que los demás serán Trabajadores.
El nodo manager será el punto de entrada para todas las operaciones que hagamos con el Swarm. Vale aclarar que los nodos Manager funcionan también como Trabajadores.
Una vez creadas, confirmamos la operación y el estado de los nodos ejecutando
$ docker-machine ls
NOMBRE ACTIVO DRIVER ESTADO URL SWARM DOCKER ERRORES
manager - virtualbox Running tcp://192.168.99.100:2376 v17.11.0-ce
nodo1 - virtualbox Running tcp://192.168.99.101:2376 v17.11.0-ce
nodo2 - virtualbox Running tcp://192.168.99.102:2376 v17.11.0-ce
Es importante que guardemos el IP del nodo manager (192.168.99.100) ya que lo usaremos pronto.
Creación del Swarm
El siguiente paso consiste en inicializar el Swarm desde el nodo manager y subscribir a los demás Trabajadores.
Para esto vamos a conectarnos primero con el manager utilizando docker-machine.
$ eval $(docker-machine env manager)
Y luego correr el comando que inicializa a docker (del manager) en modo Swarm.
$ docker swarm init --advertise-addr 192.168.99.100
Swarm initialized: current node (lf2kfkj0442vplsxmr05lxjq) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join \
--token SWMTKN-1-5g6cl3sw2k76t76o19tc45cnk2b90f9e6vl7rj9iovdj0328o8-a1d8uz0jpya9ijhw2788bqb2p \
192.168.99.100:2377
To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
El flag --advertise-addr especifica la dirección que utilizarán los Trabajadores para registrarse al Swarm. Nosotros usaremos la IP que nos dió previamente docker-machine, aunque en una red interna, es mejor utilizar IPs privadas.
Copiamos el comando. Si necesitamos volver a obtenerlo podemos correr uno de estos dos comandos (siempre desde el manager), dependiendo de si queremos subscribir un Trabajador o un Manager.
$ docker swarm join-token worker
$ docker swarm join-token manager
Subscripción de nodos Trabajadores
Una vez que tenemos creado el Swarm en nuestro nodo Manager, debemos pasar a registrar a los nodos Trabajadores.
Para esto nos conectaremos a uno de los Trabajadores utilizando docker-machine
$ eval $(docker-machine env nodo1)
Y correremos el comando obtenido previamente, exactamente como lo copiamos.
$ docker swarm join \
--token SWMTKN-1-5g6cl3sw2k76t76o19tc45cnk2b90f9e6vl7rj9iovdj0328o8-a1d8uz0jpya9ijhw2788bqb2p \
192.168.99.100:2377
This node joined a swarm as a worker
Una vez que repitamos estos dos pasos para cada uno de los Trabajadores, podremos verificar nuestro Swarm volviendo a conectarnos al Manager (con docker-machine) y corriendo:
$ docker node ls
ID HOSTNAME ESTADO DISPONIBILIDAD MANAGER
lf2kfkj0442vplsxmr05lxjq manager Ready Active Leader
1m9rdh9hlkktiwaz3vweeppp nodo1 Ready Active
pes38pa6w8xteze6dj9lxx54 nodo2 Ready Active
Si todo funcionó correctamente, vamos a obtener una vista de todos los nodos que componen nuestro cluster, indicando cuál es el Manager (Leader) y el estado de cada uno.
Despliegue de la aplicación
En este punto ya tenemos el Swarm creado, compuesto por 3 nodos, uno de ellos Manager y los demás Trabajadores. Como comenté anteriormente, el Manager será el nodo desde el cual operaremos sobre el cluster, de modo que nos conectamos al mismo.
$ eval $(docker-machine env manager)
¡Ya estamos listos para desplegar nuestro Stack! Pero antes de hacerlo, vamos a repasar un poco de la nueva terminología introducida por Swarm:
- un Stack es una colección de Services que componen nuestro sistema. Se escribe en un archivo YML de forma similar a un archivo
docker-compose.yml, con services, networks, volumes, etc. - un Service es un componente concreto de nuestro sistema. Éste define, al igual que un
docker-compose.yml, su imagen base, variables de entorno, comando a correr, etc. En el contexto de un Swarm, los Services además pueden incluir detalles dedeploypara un entorno específico (cantidad de réplicas, restart_policy, etc.). - las Task se ubican un nivel por debajo de los Services, y representan instancias concretas de los mismos, son containers en ejecución dentro de un Nodo compatible. Swarm iniciará una Task por cada réplica que requiera cada Service.
- los Nodos son las unidades de tabajo que dispondrá Swarm para correr las Tasks. Al ser Manager, un Nodo también será el host docker desde donde podremos interactuar con el Swarm.
Si bien Docker permite la creación de Swarm Services de forma manual, aquí vamos a enfocarnos crearlos a través de archivos .yml de stack (similar a docker-compose vs docker run).
Para nuestro ejemplo, vamos a tomar la clasica App de votación de dockersamples que consiste en 5 services (algunas propiedades fueron eliminadas para una mayor simplicidad):
version: "3"
services:
redis:
imagen: redis:alpine
puertos:
- "6379"
despliegue:
replicas: 1
politica_de_reinicio:
condicion: en_falla
db:
imagen: postgres:9.4
deploy:
colocacion:
restricciones: [modo.rol == manager]
app:
imagen: private-repository/image-name:latest
puertos:
- 5000:80
depende_de:
- redis
- db
despliegue:
replicas: 2
politica_de_reinicio:
condicion: en_falla
visualizer:
imagen: dockersamples/visualizer:stable
puertos:
- "8080"
volumenes:
- "/var/run/docker.sock:/var/run/docker.sock"
despliegue:
colocacion:
restricciones: [modo.rol == manager]
Como se puede ver, un docker-stack.yml es muy parecido al tradicional docker-compose.yml. La mayor diferencia es el nuevo elemento deploy, que es utilizado por Docker para customizar las opciones de despliegue para nuestros Services en el contexto de un Swarm.
En nuestro ejemplo solo utilizamos unas pocas opciones de deploy, pero vale la pena detenerse en la documentación sobre este punto ya que aquí se encuentra el mayor poder de Swarm.
Para desplegar nuestro Stack en el Swarm, correremos el siguiente comando:
$ docker stack deploy -c docker-stack.yml mystack
Creating network mystack_default
Creating service mystack_result
Creating service mystack_worker
Creating service mystack_visualizer
Creating service mystack_redis
Creating service mystack_db
Creating service mystack_vote
El último argumento es el nombre del Stack, el cual servirá de prefijo para todos los Services y para usar en ciertos comandos.
A partir de este momento, Swarm comenzará el despliegue creando una Task por cada una de las réplicas de nuestros Services, lo cual terminará siendo sencillamente un container en alguno de los nodos disponibles.
Monitoreo del Swarm
El proceso de despliegue puede tomar un tiempo en terminar, dependiendo del tamaño del stack, pero Swarm ofrece varios comandos para monitoreo, como por ejemplo (siempre conectado al Manager):
- Listar los Stacks creados:
$ docker stack ls
NOMBRE SERVICES
mystack 6
- Listar Services del Stack:
$ docker stack services mystack
ID NOMBRE MODO REPLICAS IMAGEN PUERTOS
edq3ekyi2fm0 mystack_worker replicated 0/1 dockersamples/examplevotingapp_worker
o6c2uzibyjsn mystack_result replicated 1/1 dockersamples/examplevotingapp_result:before *:5001->80/tcp
qkvq214nnrcq mystack_vote replicated 2/2 dockersamples/examplevotingapp_vote:before *:5000->80/tcp
r8xx2yfeckeg mystack_redis replicated 1/2 redis:alpine *:0->6379/tcp
ui42d228wsem mystack_visu... replicated 0/1 dockersamples/visualizer:stable *:0->8080/tcp
w6qmnih17ucs mystack_db replicated 0/1 postgres:9.4
Aqui podremos ver la cantidad de réplicas levantadas para cada Service. También podemos ver que algunas de ellas no están levantadas todavía. Por ejemplo, el Service app todavía no levantó la segunda réplica.
- Listar Tasks del Stack:
$ docker service ps mystack
ID NOMBRE IMAGEN NODO ESTADO DESEADO ESTADO ACTUAL ERROR PUERTOS
tvbmsi6fdrnf mystack_worker.1 dockersamples/examplevotingapp_worker node1 Running Running 6 minutes ago
pcahy7rhiw5d mystack_vote.1 dockersamples/examplevotingapp_vote:before node1 Running Running 13 minutes ago
s4qtcjypq69l mystack_vote.2 dockersamples/examplevotingapp_vote:before manager Running Running 9 minutes ago
tobpx1qa14k9 mystack_db.1 postgres:9.4 node2 Running Running 5 minutes ago
taszc0iqdudj mystack_redis.1 redis:alpine node2 Running Running 7 minutes ago
t2uoqi4lnt15 mystack_result.1 dockersamples/examplevotingapp_result:before manager Running Running 11 minutes ago
kil75smj8jtk mystack_redis.2 redis:alpine node1 Running Running 12 minutes ago
nrug50wf3r5i mystack_visualizer.1 dockersamples/visualizer:stable manager Running Running 7 minutes ago
Lo que es interesante de este listado es que se puede observar en qué nodo se encuentra cada Task específica, además de si hay algún error.
- Ver el log de un Service en particular (compuesto por todas las réplicas):
$ docker service logs mystack_app
Habrán notado que en el stack había un Service llamado visualizer que no era parte de nuestro sistema. Este componente expone una página web con una representación gráfica del Swarm, actualizada en tiempo real, junto con detalles relevantes de cada Task.
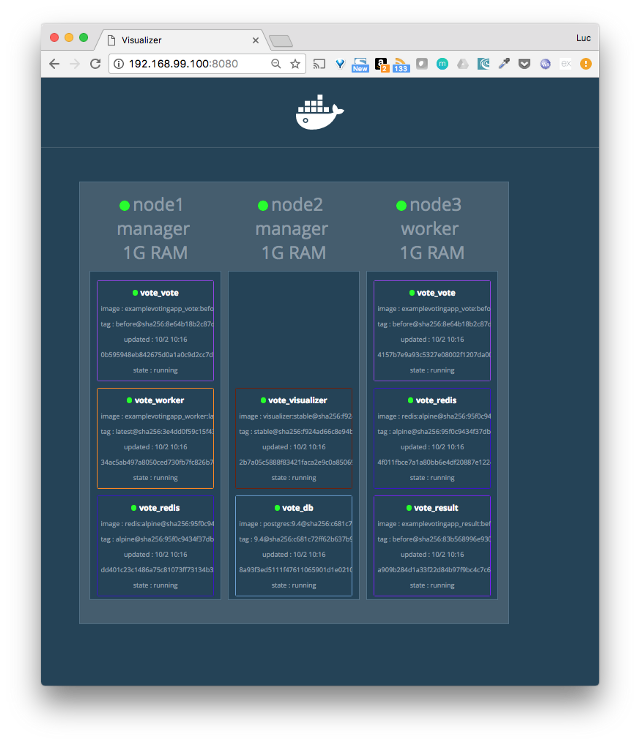
Routing Mesh y acceso a los Services
Swarm ofrece dos estrategias alternativas para resolver el acceso a los Services desde el exterior. La forma más simple se denomina Routing Mesh y funciona de la siguiente manera:
Si tomamos el Service app de ejemplo, veremos que tiene el siguiente port-mapping 5000:80. Esto significa que podremos acceder al puerto 5000 apuntando a la dirección IP de cualquiera de los nodos del Swarm, y Docker resolverá al Task correspondiente de forma transparente (¡Que cool!).
Para el caso de un Service con más de una réplica (como por ejemplo app), Swarm resolverá el balanceo de carga también de forma transparente, de modo que cada vez que accedamos a 192.168.99.100:5000, resolverá el request contra alguno de los Task de app rotativamente.
El Routing Mesh es una de las funciones más atractivas de Swarm, y probablemente sirva para la mayoría de los casos. Para los que no, Swarm ofrece otras formas de configuración manual de Service Discovery y Load Balancing.
Conclusión
La configuración y puesta en marcha de un Docker Swarm ha resultado una experiencia muy positiva. Se encuentra guiado por una excelente documentación y permite configurar una infraestructura compleja, con capacidades avanzadas de administración, monitoreo, y troubleshooting sin poseer conocimientos profundos sobre manejo de servidores, configuración de redes, seguridad, etc.