
Java Micro benchmarks (or how to enjoy holidays)
Brief tutorial for setting up a jmh project to measure performance of java code using micro benchmarks


Introduction
Coding is a team work. There's no doubt in that.
If you code with smart people, you will often find yourself on the fun side of coding: arguing about code. There isn't more passionate people than programmers arguing about code, challenging structures, frameworks, languages, etc.
What's funnier than that, is converting opinions into facts. Putting two divergent opinions to test makes something wonderful happen. What began as a competitive game, turns into a collaborative one. Once you find both of you were wrong, you start to collaborate into making the code work better. (Only if egos are under control).
Today I'd like to show you a simple tool for doing exactly that on Java. A tool for doing micro benchmarks correctly.
Be able to assert your assumptions on what code is best in terms of performance, directly from your IDE without any additional commands.
Java Microbenchmark Harness
JMH is tool developed by the guys on OpenJdk that aims at testing microbenchmarks correctly.
As you know Java uses the JVM that behaves strangely for micro tests because it optimizes the execution of your code over time. If you test naively, the impact of that optimization can change your test results completely (i.e. depending on the order of test).
JMH did a wonderful job at abstracting those details for you and being able to focus on the tests themselves. I'm not going to explain all the config options, or the different setups. This post is going to show you just one possible setup to test different code pieces, so you can adapt to your needs. As an example we will doing insertion sort algorithm on different primitive collection libraries.
For other options (setup, measuring, or calibration) look at the examples. They are the best source of documentation I've found so far.
Step 1 - Create a maven project with the testable code
Because JMH manages the VM startup process to do the test correctly, you will want your tested code separate from the testing code. That's to ensure that the code you write for the tests doesn't affect the code being tested.
Since we are going to test 2 different primitive collection libraries, lets include them as dependencies.
<?xml version="1.0" encoding="UTF-8"?>
<project xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd" xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<modelVersion>4.0.0</modelVersion>
<groupId>ar.com.kfgodel</groupId>
<artifactId>intro-to-algo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<dependencies>
<!-- Allow faster primitive collections -->
<dependency>
<groupId>net.sf.trove4j</groupId>
<artifactId>trove4j</artifactId>
<version>3.0.3</version>
</dependency>
<!-- Additional primitive collections -->
<dependency>
<groupId>colt</groupId>
<artifactId>colt</artifactId>
<version>1.2.0</version>
</dependency>
</dependencies>
</project>
Step 2 - Define the code to be tested
We want to compare the performance of different collections when doing insertion sort. So I'm defining different insertion sort classes for each collection type. They look something like this:
public class InsertionSortIntegerListSorter implements IntegerListSorter {
@Override
public List<Integer> sort(List<Integer> input) {
... details...
}
}
Varying the type of collection according to the tested library
Trove
public class InsertionSortTroveIntegerListSorter implements Sorter<TIntArrayList> {
@Override
public TIntArrayList sort(TIntArrayList input) {
...details...
}
}
public class InsertionSortColtIntegerListSorter implements Sorter<IntArrayList> {
@Override
public IntArrayList sort(IntArrayList input) {
...details..
}
}
Take a list, sort it, return the result.
Step 3 - Create a maven project with the testing code
Here is where we define how are we going to test our code. We will need of course JMH as a dependency:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>ar.com.kfgodel.intro-to-algo</groupId>
<artifactId>algo-benchmarks</artifactId>
<version>${intro-to-algo.version}</version>
<packaging>jar</packaging>
<name>JMH benchmark sample: Java</name>
<dependencies>
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-core</artifactId>
<version>1.19</version>
</dependency>
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-generator-annprocess</artifactId>
<version>1.19</version>
<scope>provided</scope>
</dependency>
<!-- Tested dependency -->
<dependency>
<groupId>ar.com.kfgodel</groupId>
<artifactId>intro-to-algo</artifactId>
<version>${intro-to-algo.version}</version>
</dependency>
</dependencies>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<javac.target>1.8</javac.target>
<intro-to-algo.version>0.0.1-SNAPSHOT</intro-to-algo.version>
</properties>
<build>
<plugins>
...details on creating a single jar...
</plugins>
</build>
</project>
Step 4 - Define your testing code
JMH has different modes for what you want to measure and how to do it.
Throughput: operations per unit of time (default)AverageTime: average time per operationSampleTime: samples the time for each operation (not all operations are measured)SingleShotTimemeasures the time for a single operation (if you want to account for cold startup time)
In this example we want to compare the amount of operations each option can handle given an amount of time. So we are sticking with the default.
For configuring the tests you can use annotations or programmatically, I prefer doing it programmatically because it's easier to change.
@State(Scope.Benchmark)
public class PrimitiveCollectionsBenchmark {
private InsertionSortIntArraySorter arraySorter = InsertionSortIntArraySorter.create();
private InsertionSortTroveIntegerListSorter troveListSorter = InsertionSortTroveIntegerListSorter.create();
...more initialization...
@Benchmark
public void noOpZero() {
// This is a reference test so we know what the best case is on this machine
}
@Benchmark
public void insertionSortIntArraySorter() {
arraySorter.sort(createTestArray());
}
@Benchmark
public void insertionSortIntegerListSorter() {
List<Integer> elements = Arrays.stream(createTestArray())
.mapToObj(Integer::valueOf)
.collect(Collectors.toList());
listSorter.sort(elements);
}
@Benchmark
public void insertionSortTroveIntegerListSorter() {
troveListSorter.sort(TIntArrayList.wrap(createTestArray()));
}
...more benchmark methods...
private int[] createTestArray() {
return new int[]{5, 2, 4, 6, 1, 3};
}
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder()
.include(PrimitiveCollectionsBenchmark.class.getSimpleName())
.warmupIterations(5)
.measurementIterations(5)
.timeUnit(TimeUnit.MICROSECONDS)
.forks(1)
.build();
new Runner(opt).run();
}
}
Step 5 - Run the tests
If you use Idea for developing this class is runnable. Just run it like you would do with a test, and compare results.
If you don't have IDE support, you need to run JMH as a Java program from the command line and pass the uber jar that got generated by maven.
mvn install (on the testable project)
mvn package (on the tester project)
java -jar target/benchmarks.jar (on the tester project)
# Run complete. Total time: 00:01:36
Benchmark Mode Cnt Score Error Units
PrimitiveCollectionsBenchmark.insertionSortColtIntegerListSorter thrpt 5 38.340 ± 1.537 ops/us
PrimitiveCollectionsBenchmark.insertionSortIntArraySorter thrpt 5 50.134 ± 0.871 ops/us
PrimitiveCollectionsBenchmark.insertionSortIntegerListSorter thrpt 5 7.183 ± 0.158 ops/us
PrimitiveCollectionsBenchmark.insertionSortTroveIntegerListSorter thrpt 5 45.658 ± 0.695 ops/us
PrimitiveCollectionsBenchmark.noOpZero thrpt 5 3806.233 ± 15.300 ops/us
What did just happen?
So you get the idea, but you want to understand what is happening behind the scenes.
First thing to notice is that we create a single class that acts as a definition of what we test. The class is the container and entry point of all the tests that are going to be run, and compared together.
This class is annotated with @State(Scope.Benchmark) which means that instance variables are shared among tests.
Then, each test is defined with a method annotated with @Benchmark. Pretty much like junit.
JMH knows that it should run a test method as many times as it can before time runs up, making sure to warm up the VM previously, before taking measurements.
# Run progress: 33.33% complete, ETA 00:01:04
# Fork: 1 of 1
# Warmup Iteration 1: 6.673 ops/us
# Warmup Iteration 2: 7.695 ops/us
# Warmup Iteration 3: 7.769 ops/us
# Warmup Iteration 4: 7.644 ops/us
# Warmup Iteration 5: 7.747 ops/us
Iteration 1: 7.740 ops/us
Iteration 2: 7.720 ops/us
Iteration 3: 7.754 ops/us
Iteration 4: 7.743 ops/us
Iteration 5: 7.741 ops/us
Finally you have the main method that configures the runner with benchmark parameters:
.warmupIterations(5)
.measurementIterations(5)
.timeUnit(TimeUnit.MICROSECONDS)
We are telling JMH that we want 5 non measured iteration to warm up the vm, and then 5 more iteration for measuring each test. JMH will take measures for each test and analyze the deviation. Depending on them you need to adjust the parameters.
Beware of the compiler
One thing you need to be aware of is that the compiler is really good at optimizing your code. And some times it won't run at all. Some times you need to trick the compiler into thinking your code generates side effect.
That's when the JMH blackhole comes into help. just be warned so it doesn't surprise you that some test run amazingly fast.
Conclusion
JMH it's really easy to use once you understand how it works, and really fast if you do it on the IDE. If you need to optimize your code, or just compare different options I recommend you adopt it and keep it on your dev backpack.
It has way more options that what we used today (i.e. being able to fork different vms, or parameterizing the tests). Look for details on the samples.
Bonus track
This is the comparison chart for primitive libraries doing insertion sort.
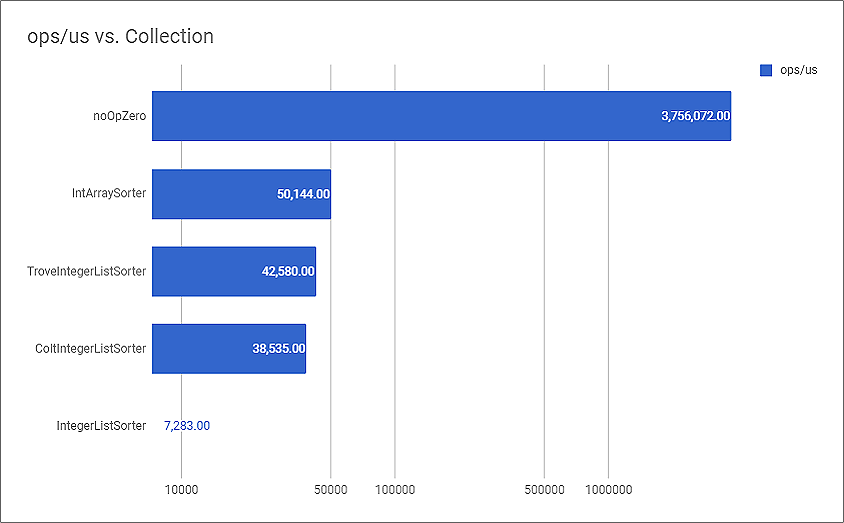
I've never expected Trove to be so close to the array, even better than Colt. Java collection on the other hand suffers from autoboxing, which is slower of course.